컬렉션 프레임워크
객체를 담을 수 있는 신축성 있는 주머니이다.
객체가 아닌 것 ex. int, double, 등등..은 Wrapper class를 이용해서 객체로 변환 가능

참고로 인터페이스끼리는 상속이 가능하다. 인터페이스끼리 상속할 땐 다중 상속이 가능하다. 당연히 인터페이스끼리 구현은 불가하다. 구현은 일반 클래스에서 implements를 쓰고 구현해야 하기 때문이다.
public interface Animals extends IBird, IFlay { // 인터페이스 간 다중 상속 가능
public void go();
public void run();
}
따라서 Collection은 List가 상속하는 구조이고, 인터페이스를 구현해야 하는 클래스 입장(LinkedList)에서는 구현하고 있다고 보면된다.
클래스끼리도 상속이 가능하다. 다만 클래스는 상속을 받을 때는 다중 상속이 불가능하다. 인터페이스 다중 구현은 되지만, 다중 상속은 불가한 것이다. 추상 클래스를 상속받을 때에도 다중 상속이 불가능하다.
따라서 정리해보면 인터페이스를 구현하거나 상속할 땐 받는 쪽의 입장에서 (각각 일반 클래스, 인터페이스) 다중 구현 및 다중 상속이 가능하지만, 클래스 또는 추상 클래스를 상속할 땐 다중 상속이 불가하다고 볼 수 있다.
예시 코드
List a = new ArrayList<>();
다형성을 이용하여 List 인터페이스 타입의 참조변수를 ArrayList 클래스 객체로 생성할 수 있음.
| 인터페이스 | 특 징 |
| List | 순서가 있는 데이터의 집합, 데이터의 중복을 허용한다. --> 데이터를 add하면 앞에서 부터 순차적(순서대로)으로 데이터가 들어간다. 그래서 각각의 저장되어 있는 공간들은 고유한 index를 갖는다. ex.) 대기자 명단 |
| 구현 클래스: ArrayList, LinkedList, Stack, Vector등 |
|
| Set | 순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않는다. --> 집합이다. 데이터가 순서와는 상관없이 add된다. 중복되지 않는다. ex.) 양의 정수 집합, 소수의 집합 |
| 구현 클래스: HashSet, TreeSet등 | |
| Map | 키와 값의 쌍으로 이루어진 데이터의 집합. 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값을 중복을 허용한다. ex.) 우편번호, 지역번호 |
| 구현 클래스: HashMap, TreeMap, Hashtable, Properties등 |
Wrapper Class
기본 자료타입(primitive type)을 객체로 다루기 위해서 사용하는 클래스들을 래퍼 클래스(wrapper class)
primitive type > Class (Object)
int > Integer
long > Long
double > Double
배열 vs. 컬렉션
| 배열 | 컬렉션 | |
| 장점 | 모든 데이터 저장 가능 사용 편리 |
자동으로 크기 조절 명시적인 이름의 메소드 사용 |
| 단점 | 처음 지정한 크기에서 공간의 크기를 변경 불가 |
사용 방법 다소 복잡 |
List 컬렉션
List 컬렉션은 객체를 일렬로 늘어놓은 구조로 이루어져 있다.
객체를 인덱스로 관리하기 때문에 List 컬렉션에 객체를 추가하면 자동 인덱스가 부여된다.
인덱스는 객체를 검색, 삭제할 때 사용한다.
List 컬렉션은 객체 자체를 저장하는 것이 아닌 객체의 번지를 참조한다.
동일한 객체를 저장하는 것을 허락(이 점은 Set 인터페이스와 다른점)하는데, 이 경우에는 동일한 객체의 번지를 참조한다. 그리고 null도 저장할 수 있다.
ArrayList
ArrayList에 객체를 추가하는 순서대로 인덱스 번호가 매겨진다. (0번부터)
배열의 크기를 선언하지 않아도 괜찮음
선언 시 명시한 데이터 타입의 객체 10개 저장 공간이 생김
ArrayList<객체의데이터타입> 변수명 = new ArrayList<객체의데이터타입>();
// 컬렉션 클래스는 객체만 담을 수 있음!!
// primitive data type의 경우 wrapper class로 객체화 한 것만 담을 수 있음
ArrayList<Integer> 변수명 = new ArrayList<Integer>(); // Generics 명시한 "객체"의 데이터 타입만 저장
ArrayList<String> 변수명 = new ArrayList<String>();
List<Student> 변수명 = new ArrayList<Student>(); // 인터페이스의 다형성 이용
remove(int idx), remove(Object obj)
remove(Object obj)를 의도했지만, 인덱스로 인식되어 객체가 아닌 인덱스의 elem이 삭제된다.
이것의 원인은 int 타입의 param을 넣었을 때 int 타입이고 Object 타입이 아니기 때문에 param 타입이 일치하는 remove(int idx)로 인지되기 때문이다.
즉, 간단히 말하면 뭐가 먼저 인지되고 이런 법칙(?)이 있는 게 아니라, 오버로딩 되어있는 ArrayList 클래스의 remove 함수들의 param 시그니처 데이터 타입이 다르기 때문에 일치하는 remove(int idx) 로 인지되는 것일 뿐이다.
// ArrayList 클래스의 오버로딩되어 있는 remove 함수들
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
따라서 int 타입의 Object 자체를 삭제해주기 위해선 autoboxing (원시 타입의 값을 해당하는 wrapper 클래스의 객체로 바꾸는 과정) 과정을 컴파일러가 수행하도록 놔두는 게 아니라, 직접 Object 타입의 객체로 넣어주면 의도대로 동작시킬 수 있다.
You can see that the second call is also treated as remove(index). The best way to remove ambiguity is to take out autoboxing and provide an actual object, as shown below.
두 번째 호출도 remove(index)로 처리되는 것을 볼 수 있습니다. 모호성을 제거하는 가장 좋은 방법은 아래와 같이 오토박싱을 제거하고 실제 개체를 제공하는 것입니다.
System.out.println("ArrayList Before : " + numbers);
// Calling remove(index)
numbers.remove(1); //removing object at index 1 i.e. 2nd Object, which is 2
//Calling remove(object)
numbers.remove(new Integer(3)); // autoboxing 과정을 생략하고 object 타입의 객체를 직접 넣어줌
System.out.println("ArrayList After : " + numbers);
Output :
ArrayList Before : [1, 2, 3]
ArrayList After : [1]AutoBoxing vs. UnBoxing
AutoBoxing (int -> Integer)
원시 타입의 값을 해당하는 wrapper 클래스의 객체로 바꾸는 과정을 의미
자바 컴파일러는 원시 타입이 아래 두 가지 경우에 해당될 때 autoBoxing을 적용한다.
Passed as a parameter to a method that expects an object of the corresponding wrapper class.
Assigned to a variable of the corresponding wrapper class.
원시타입이 Wrapper 클래스의 타입의 파라미터를 받는 메서드를 통과할 때
원시 타입이 Wrapper 클래스의 변수로 할당될 때
UnBoxing (Integer -> int)
Wrapper 클래스 타입을 원시 타입으로 변환하는 과정의 의미
ex) Integer -> int
자바 컴파일러는 원시타입이 아래 두 가지 경우에 해당될 때 unBoxing을 적용한다.
Wrapper 클래스 타입이 원시 타입의 파라미터를 받는 메서드를 통과할 때
Wrapper 클래스 타입이 원시 타입의 변수로 할당될 때
기본 타입 vs. 박싱된 기본 타입(객체 인스턴스)
매개변수를 사용할 때 래퍼클래스보단 기본타입을 사용하는 게 좋다..?
그러나 VO(Entity)에선 객체 타입을 사용하는 게 더 좋다..?
식별성의 유무
기본 타입은 순수하게 값만 가지고 있지만 박싱된 기본 타입은 값에 더해 식별성이라는 추가적인 값을 더 가지고 있습니다. 즉, 박싱된 기본 타입의 인스턴스들은 값은 같지만 서로 다르다고 식별될 가능성이 있습니다. 보다 쉽게 말하자면, 박싱된 기본 타입이 가지는 식별성은 메모리 주소로 볼 수 있습니다.
정리하면, 기본타입은 순수하게 값만 가지고 있어서 식별성을 따질 때 의도대로 동작할 가능성이 높지만,
박싱된 기본타입은 저장되어 있는 게 객체의 주소값이므로 == 과 같이 식별성을 따질 때 객체 자체의 값은 같지만 서로 다른 객체를 가리킬 가능성(주소가 다름)이 있어 의도대로 동작하지 않을 가능성이 높음
따라서 기본타입을 사용하는 걸 권장
null을 가질 수 있는가 여부
기본 타입은 언제나 유효한 값을 가지고 있으나 박싱된 기본 타입은 null을 가질 수 있습니다. 이는 객체 인스턴스가 가지고 있는 특징을 따라가는데요, 박싱된 기본 타입은 객체이기 때문에 당연히 null을 가질 수 있습니다. 그런데, 이러한 특징으로 인해 VO 객체에서 박싱된 기본 타입을 사용하게 되는 큰 이유가 되기도 합니다.
VO or Entity에선 Long을 사용하는 게 왜 좋을까
결론부터 말하면,
큰 수의 범위를 사용하는 id 값의 초기값을 null을 줄 수 있어야
id가 실제로 0인건지 null인건지(아예 없는 건지) 알 수 있기 때문!
이처럼 박싱된 기본 타입을 jpa에서 사용하는 이유는 재미있게도 박싱된 기본 타입에서 문제로 지적된 null 허용과 관련이 있습니다.
특정 id값의 타입 지정 시 mybatis를 사용하나 jpa를 사용하나 기본적으로 int보다 long이 더 큰 값 범위를 가지고 있기 때문에 int 대신 long을 사용하는데, 여기서 발생하는 문제는 기본 타입을 사용했을 때의 초기값입니다.
기본 타입의 경우 초기값이 0입니다. 예를 들어 id의 타입을 long(기본 타입)으로 지정했을 경우 실제로 사용하는 id 값이 없는 것인지, 0인건지 구분할 수 없게 됩니다. 이 때 박싱된 기본 타입(wrapper class)인 Long을 사용하게 되면 id가 0인지 없는 것인지 null을 통해 명확하게 구분할 수 있게 되는 것입니다. 즉, null로 인해 id값이 없다는 것을 보장할 수 있게 되는 것입니다.
https://velog.io/@power0080/Wrapper-클래스와-기본타입
HashMap

Map은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조입니다.
여기서 키와 값은 모두 객체입니다.
값은 중복 저장될 수 있지만 키는 중복 저장될 수 없습니다.
만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치됩니다. (하나의 키에 두 개의 값을 저장 불가!)
데이터 저장의 순서를 보장하지 않고 key-value로 저장됨
키에 대한 Hash 값(키와 원소의 위치를 매핑)을 저장하고 조회
HashMap은 이름 그대로 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데 있어서 뛰어난 성능을 보입니다.
Hashing
해시 함수란 키 값을 원소 위치로 변환하는 함수이다.
해시 테이블이란 해시 함수에 의해 계산된 주소에 저장할 값을 저장한 표이다.

HashTable
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.

예를 들어 우리가 (Key, Value)가 ("John Smith", "521-1234")인 데이터를 크기가 16인 해시 테이블에 저장한다고 하자. 그러면 먼저 index = hash_function("John Smith") % 16 연산을 통해 index 값을 계산한다. 그리고 array[index] = "521-1234" 로 전화번호를 저장하게 된다.
이러한 해싱 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 해시테이블의 평균 시간복잡도는 O(1)이다.
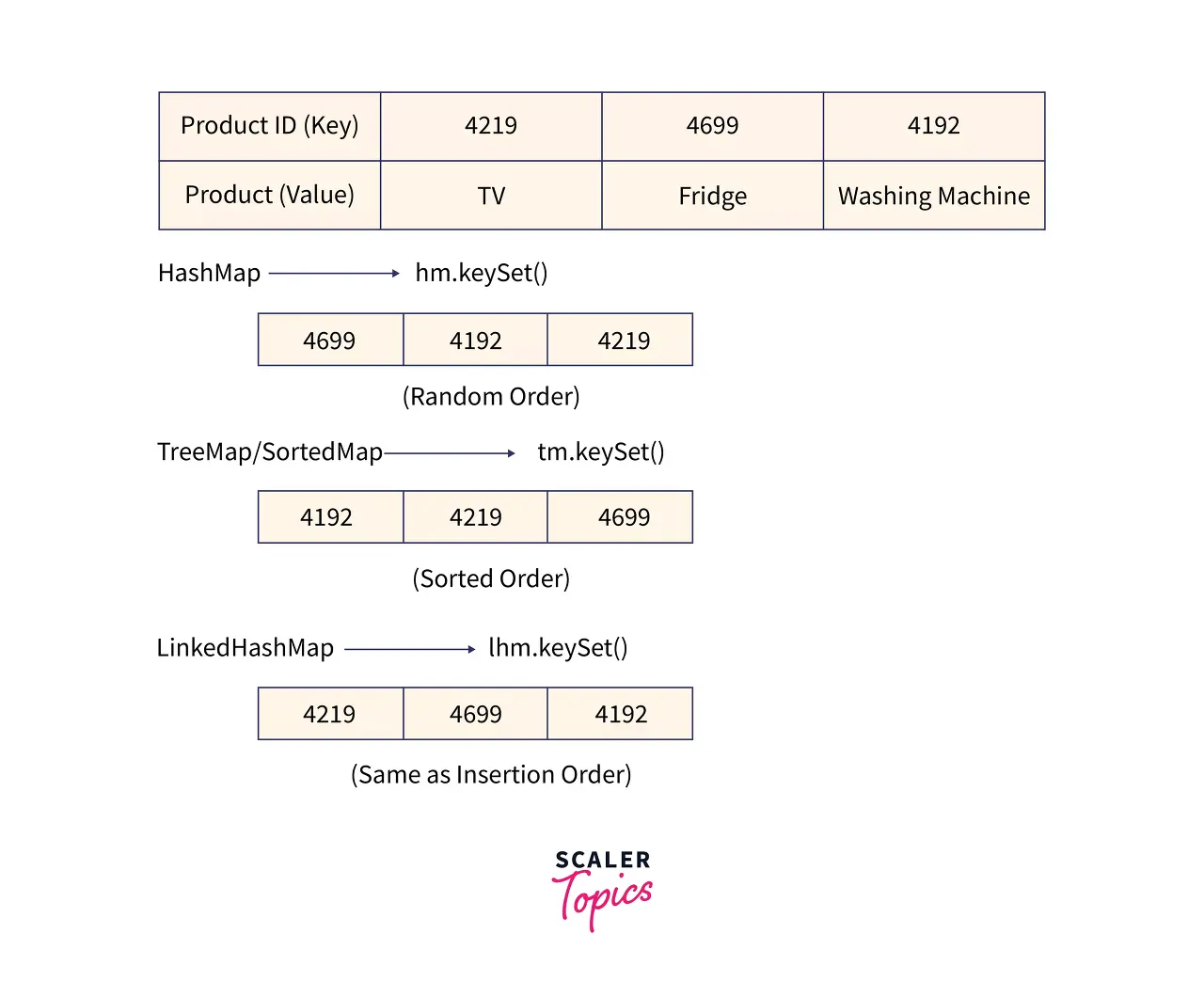
keySet()
The keySet() method in HashMap returns keys in random order. In LinkedHashMap, it returns keys in insertion order (the same order in which we insert the values), and in TreeMap and SortedMap, it returns keys in sorted order.
HashMap의 keySet() 메서드는 무작위 순서로 키를 반환합니다. LinkedHashMap에서는 삽입 순서(값을 삽입하는 것과 동일한 순서)로 키를 반환하고 TreeMap 및 SortedMap에서는 정렬된 순서로 키를 반환합니다.
'JAVA' 카테고리의 다른 글
| [OOP, Java] 다형성 & 상속 & 객체 변수 형변환 그림으로 정리 (0) | 2023.09.11 |
|---|---|
| [Java] 예외처리 (0) | 2023.06.22 |
| [Java] 추상클래스 vs. 인터페이스 (0) | 2023.06.21 |
| [Java] Object 클래스, 다형성 (0) | 2023.06.20 |
| [Java] 오버로딩, 오버라이딩 (0) | 2023.06.19 |



